概述
探针是用来定期对容器的健康状态进行检查,根据探针结果来决定是否重启Pod和是否将流量转发给Pod。
检查机制
探针概述
目前k8s提供了四种探针机制,exec,grpc,httpGet,tcpSocket。
exec可以理解为自定义探针,当k8s其他三种探针机制不支持对自己的应用检查时,可以使用exec方式自己编写健康检查的探针。比如:你启动了一个应用,没有网络通讯能力那么可以使用exec来执行shell脚本或者其他工具来实现或者udp应用。
grpc是Google对自己东西的支持,对于基于grpc实现的应用可以使用这种方式。
httpGet是我们业务开发中比较常用的方式,并且对于后端同学使用spring boot的actuator就可以实现三个探针。
tcpSocket:对于TCP应用可以使用这个检查机制。
k8s官网对四种探针机制的说明
-
exec
在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。 -
grpc
使用 gRPC 执行一个远程过程调用。 目标应该实现 gRPC 健康检查。 如果响应的状态是 "SERVING",则认为诊断成功。 -
httpGet
对容器的 IP 地址上指定端口和路径执行 HTTP GET 请求。如果响应的状态码大于等于 200 且小于 400,则诊断被认为是成功的。 -
tcpSocket
对容器的 IP 地址上的指定端口执行 TCP 检查。如果端口打开,则诊断被认为是成功的。 如果远程系统(容器)在打开连接后立即将其关闭,这算作是健康的。
探针结果
- success
- Failure
- Unknown
为了满足以上三种探针结果,这就要求我们应用提供的探针接口返回数据满足探针要求。
httpGet
我们先来看http服务,http接口状态码返回200-399,则k8s认为success, 其他状态码为失败,最后接口无法调用或超时为Uknow。
| Http状态码 | k8s 状态 |
|---|---|
| 200~399 | success |
| 其他 | failure |
| timeout | unknown |
exec 探针
exec执行的命令成功则success,否则失败。一般理解为执行的命令返回0表示成功,其他为失败。
tcpSocket
在探测服务时,k8s会尝试打开tcp socket端口,打开成功则成功,否则失败。
三种探针类型
- livenessProbe
- readinessProbe
- startupProbe
| 探针 | 作用 |
|---|---|
| Liveness | 存活,容器是否运行正常,如果没有重启 |
| Readiness | 就绪,是否可以将流量转发给容器,就绪转发流量,未就绪剔出流量转发列表 |
| Startup | 启动,容器是否启动,没有在规定时间内启动成功重启该应用 |
三种探针的关系
liveness和readiness探针都依赖于startup探针。如果startup探针成功,那么liveness和readiness探针都会开始探测,如下图所示:
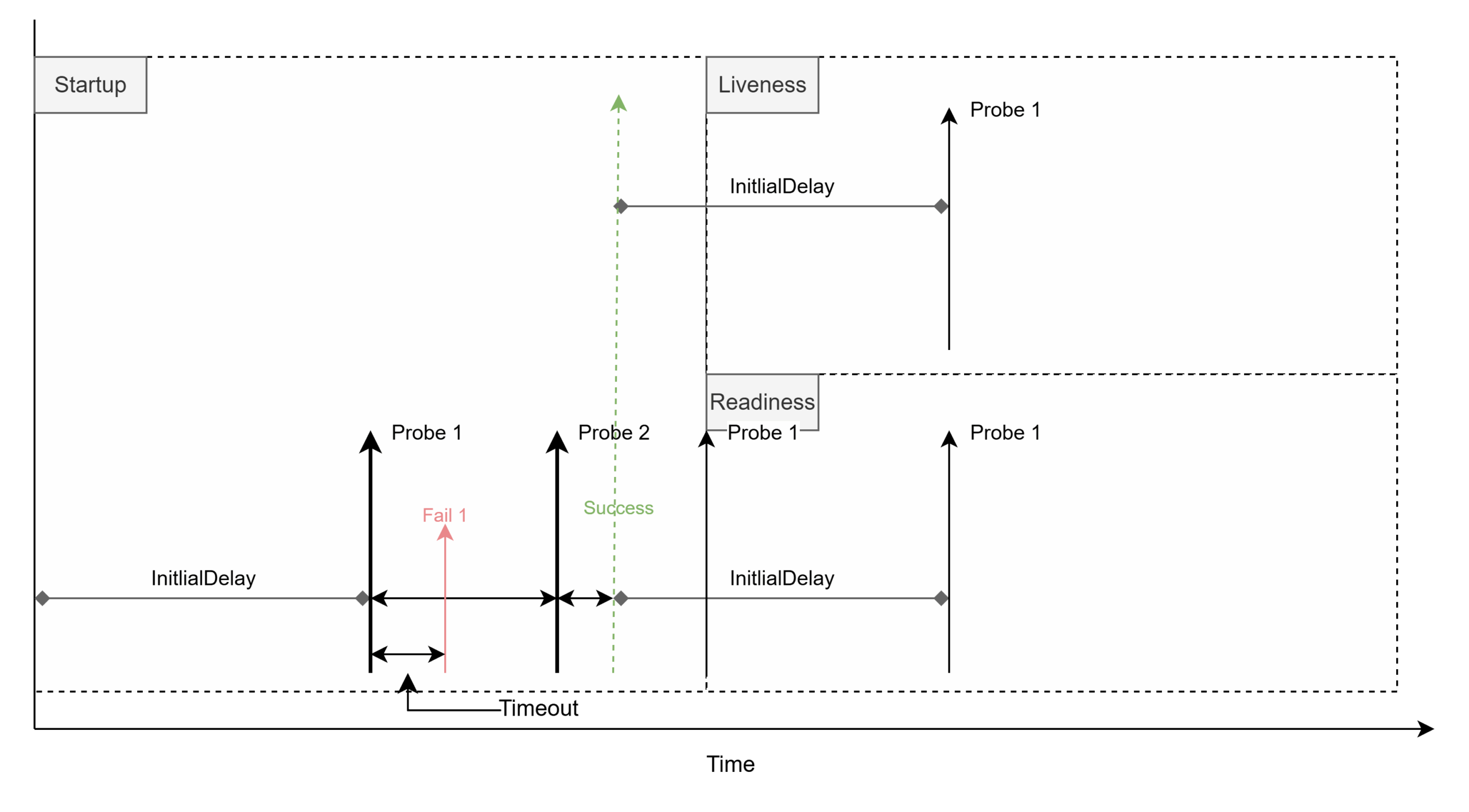
探针配置
探针时间配置
| 参数 | 作用 |
|---|---|
| initialDelaySeconds | 初始延迟秒,容器启动后启动存活态探针之前的秒数 |
| terminationGracePeriodSeconds | Pod 需要在探针失败时体面终止所需的时间长度(以秒为单位),为可选字段 |
| periodSeconds | 探针的执行周期(以秒为单位)。默认为 10 秒。最小值为 1。 |
| timeoutSeconds | 探针超时的秒数。默认为 1 秒。最小值为 1。 |
| failureThreshold | 探针成功后的最小连续失败次数,超出此阈值则认为探针失败。默认为 3。最小值为 1。 |
| successThreshold | 探针失败后最小连续成功次数,超过此阈值才会被视为探针成功。默认为 1。 存活性探针和启动探针必须为 1。最小值为 1。 |
探针时间关系
liveness探针
下图展示了liveness探针的时间线图。
livesness探针的配置的failureThreshold为3,
- 第一次探针请求成功
- 第二次,第三次和第四次请求失败
- Pod会在第四次请求后重启
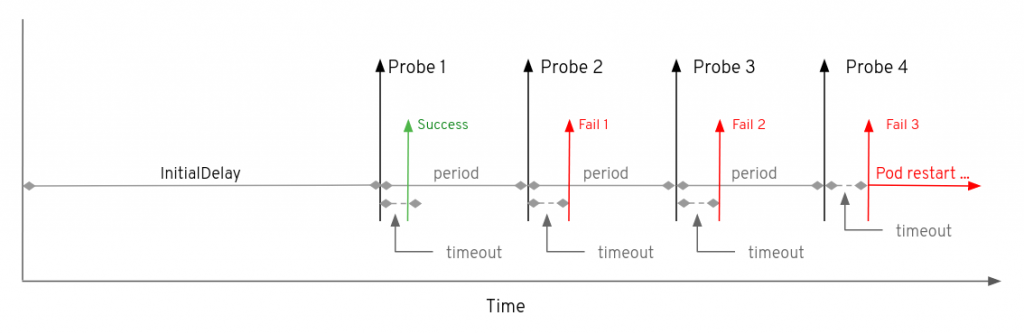
假设Pod依然没有重启成功,那么由于liveness探针而进行第二次重启需要经过的最短时间为:
time = initialDelaySeconds + failureThreshold – 1 periodSeconds + timeoutSeconds
假设在正常运行情况下,Pod已经稳定运行了一段时间,则initialDelaySeconds已经不用考虑。在这种情况下,Pod故障和Pod重启之间的最短时间为:
time = failureThreshold – 1 periodSeconds – timeoutSeconds
如下图所示,鼓掌可能发生在探测之前,也可能发生在探测之后。如果periodTime很长,是的对Pod的干扰最小,那么Pod重启启动前的时间可能导致在重启和之前添加额外的periodSeconds时间。
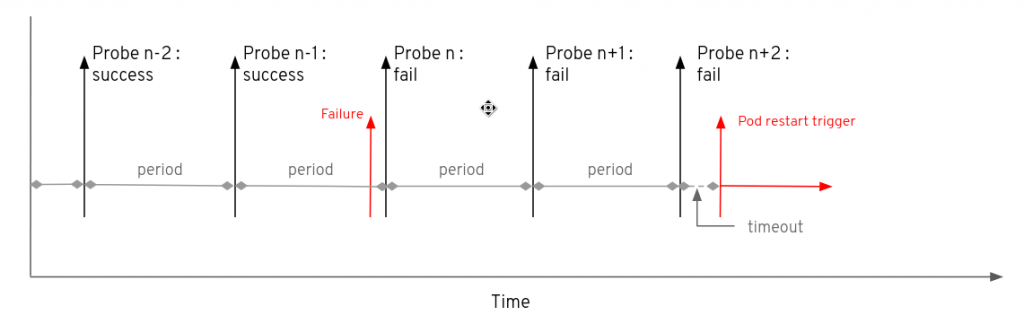
failedureThreshold参数必须谨慎设置。如果设置的太高,则存储在Pod发生故障且没有重启时浪费时间。如果设置的太低,那么可能导致Pod过早重启。
readiness探针
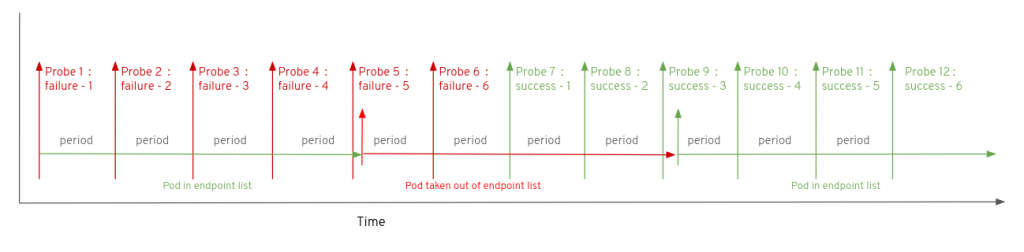
对于readiness探针,failureThreshold参数定义了在经过多少次失败之后从EndPoint中将Pod移除。
假设readiness探针的failureThreshold设置的值为5,默认successThreshold为1,那么如下图所示:刚开始Pod先连续经历了三次探测失败,紧接着一次探测成功。一次成功探测会将之前探测失败的次数清零,之后再连续经历5次探测失败后将Pod移除EndPoint,也就是负载均衡列表。
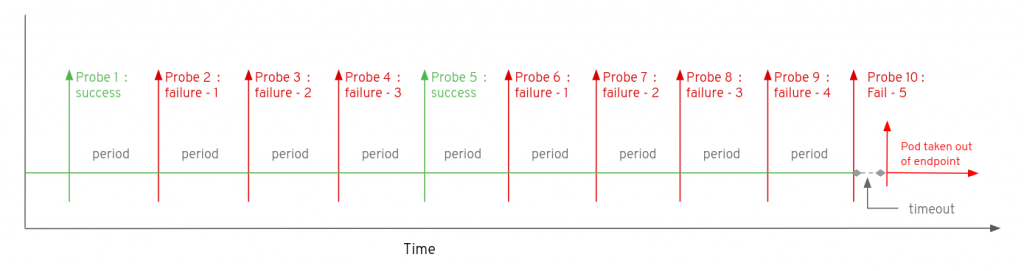
将Pod从EndPoint中移除过后,k8s依然会根据配置的时间间隔对Pod进行探测,在探测成功后且连续探测成功次数大于等于successThreshold,那么k8s会将Pod重新加入EndPoint并转发流量,如下图所示:
Spring Boot Actuator对探针的支持
Spring Boot Actuator 从2.3版本开始提供了内置对k8s Liveness和Readiness两个探针的支持,两个探针分别是:
-
/actuator/health/liveness (存活探针)
- 表示spring应用内部的状态是否有效。
-
/actuator/health/readiness (就绪探针)
- 表示spring应用是否已经准备好接受流量进行业务处理。
实现Spring Boot探针
-
增加Spring Boot Actuator 依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> -
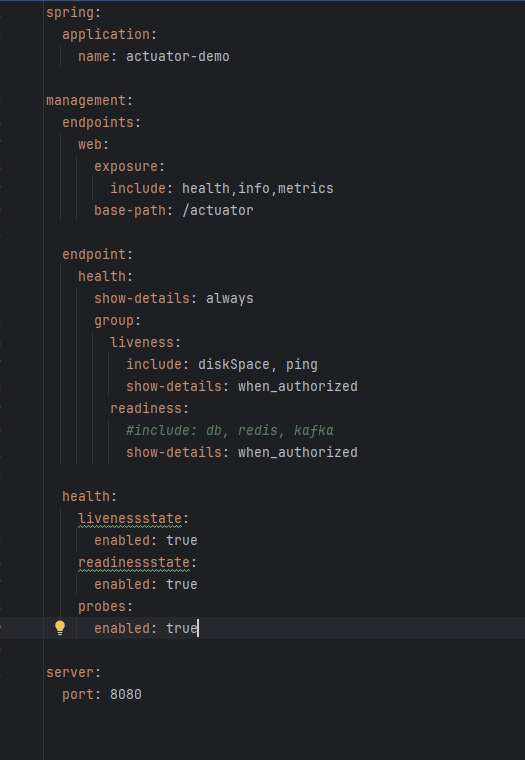
配置Application.yaml
-
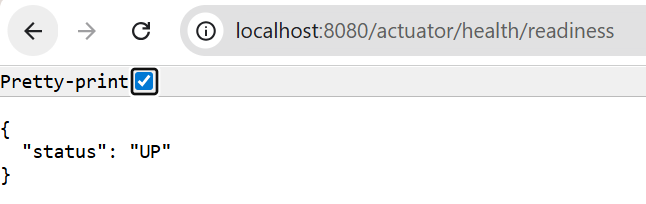
访问两个探针
没有配置探针场景
如果没有配置任何探针,那么k8s只能通过判断容器内主进程的状态。
- 存活状态
只要容器的主进程没有退出,那么k8s就认为容器存活 - 就绪状态
容器启动后, k8s立即将容器标记为就绪状态并加入服务负载均衡池(Service Selector)
潜在的问题
- 假活状态: 应用进程存活但无法处理请求(如 OOM 导致无法响应、死锁),K8s 不会重启容器,导致流量持续失败
- 提前接收流量:应用启动慢(如加载大量数据),但容器一启动就被标记为就绪,此时接收的请求会超时或失败。
- 滚动更新问题:滚动更新时,新容器启动后立即接收流量,若新版本有启动问题,会导致整个服务不可用(无探针保护)。