概述
在网络编程领域中,由于数据在不同系统之间的传输有可能会呈现出大小端的问题,因此理解大端、小端和网络字节序的概念对于编写出可移植的代码显得至关重要。
大端和小端
在计算机系统中,以字节(byte)为单位进行存储。然而,对于超过一个字节的数据类型(例如 int、long 等),它们的存储方式在不同系统之间可能会有所不同,一种是大端(Big-Endian),一种是小端(Little-Endian)。
-
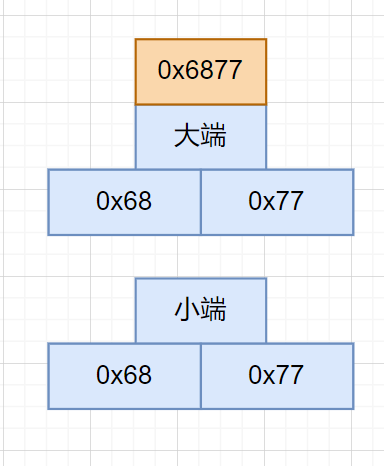
大端模式:数据的高位字节在内存中的低地址位,而低位字节则在高地址位。也就是说在这种模式下,多字节值的读取和写入是按照从高位开始优先的顺序进行的。
-
小端模式:相反,数据的低位字节则在内存中的低地址位,而高位字节则在高地址位。也即是说在这种模式下,多字节值的读取和写入是按照从低位开始优先的顺序进行的。
例如,假设有一个16位的 整数 0x6877,在大端模式下它在内存中的存储形式即为:0x68 0x77。而在小端模式下,它的存储形式则为:0x77 0x68。
网络字节序
在网络通信过程中,为了保证数据能在不同系统之间准确传输,需要使用网络字节序,它采用的是大端模式。当进行网络通信时,需要将主机字节序转为网络字节序,而在接收到数据后,需要将网络字节序再转回为主机字节序。
其中,C语言中,可以使用htons(Host TO Network Short)、htonl(Host TO Network Long)、ntohs(Network TO Host Short)和ntohl(Network TO Host Long)等函数来进行字节序的转换。
在Go语言,也有类似的函数和方法。
在Java语言中,Java默认使用大端,但是你依然可以通过位运算或者ByteBuffer转换为小端。
在网络编程过程中,保证数据传输时使用正确的字节序至关重要,这样才能确保数据可以被准确解析和处理,提高代码的可移植性和可靠性。
以下是一段使用Go语言处理大端、小端和网络字节序的示例代码:
package main
import (
"encoding/binary"
"fmt"
)
func main() {
// 0x6877是hello world的首字母hw
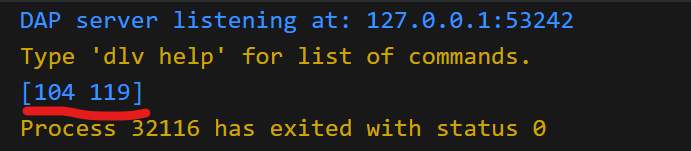
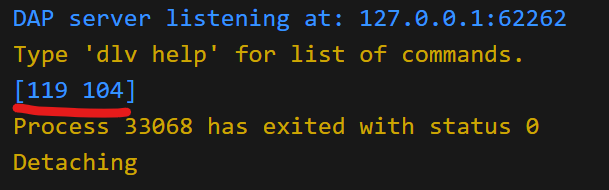
// 0x68等于十进制104
// 0x77等于十进制119
var num uint16 = 0x6877
bytes := make([]byte, 2)
binary.BigEndian.PutUint16(bytes, num)
fmt.Printf("%v\n", bytes)
}
在上述示例中,我们首先定义了一个uint16类型的变量num,并赋值为0x6877。然后我们创建了一个长度为2的byte数组bytes。使用binary.BigEndian.PutUint16()函数,将num转换为网络字节序,并存储在bytes数组中。最后,我们打印并输出bytes数组的值。
注意在示例中,我们默认使用的是大端字节序。如果你需要使用小端字节序,只需将binary.BigEndian替换为binary.LittleEndian即可。代码如下:
package main
import (
"encoding/binary"
"fmt"
)
func main() {
// 0x6877是hello world的首字母hw
// 0x68等于十进制104
// 0x77等于十进制119
var num uint16 = 0x6877
bytes := make([]byte, 2)
binary.LittleEndian.PutUint16(bytes, num)
fmt.Printf("%v\n", bytes)
}
运行截图:
总结
大端和小端是描述在多字节数据类型在内存中的存储顺序的方式。在网络编程中,我们需要特别关注这个问题,因为不同的系统可能会采用不同的存储方式,这会对数据的解析造成影响。为了确保数据在所有系统中都被正确理解和解析,我们通常会将数据转换为网络字节序(大端)进行传输,然后在接收端再将数据转换回本地的存储方式。