概述
MySQL 从8.0版本开始彻底移除了查询缓存(Query Cache),是不是我们用太多Redis导致MySQL的查询缓存没有了用武之地?其实并不是这样,主要还是因为MySQL查询缓存对MySQL的可扩展性问题和性能瓶颈的影响。下面是MySQL Blogs的原话:
scalability issues and it can easily become a severe bottleneck.Although MySQL Query Cache was meant to improve performance, it has serious scalability issues and it can easily become a severe bottleneck.
查询缓存是什么?
我比较喜欢拆字解释,我们来拆分一下:
- 查询: 查询就是我们的查询结果
- 缓存:缓存就是把查询结果放到内存中
哪类SQL会缓存哪类不会缓存?
这其实和我们平时判断是否使用Redis来缓存我们的业务数据是一样的,如果我们把查询到的数据放入缓存,但是下次请求这个缓存数据时不能使用,我们就不会把数据写入Redis。
MySQL 查询缓存命中的条件类似:
- 查询SQL与上一次的完全相同
- SQL查询到的数据没有变动
我们来看两个查询会写入查询缓存和不会写入查询缓存的示例:
1. 可能会被写入查询缓存的SQL
SELECT * FROM users WHERE username='xiaosi';如果这个SQL之前被执行过,且本次执行这条SQL时表涉及的数据没有变更,那么MySQL可能会直接从查询缓存中返回,而不会再次执行完整的查询过程。
- 可能不会被写入查询缓存的SQL
SELECT NOW(), * FROM users WHERE username='xiaosi';相比之前的SQL,我们在返回字段增加了一个NOW()函数,那么这个SQL的每次执行结果都是不一样的,结果会因为当前时间的变化而变化,所以这个查询结果不会被缓存到查询缓存中。
查询缓存的工作工程
- 首先判断这个SQL是SELECT语句
- 然后将完整的SELECT SQL语句进行哈希
- 查找查询缓存哈希表
- 如果能匹配到之前的查询结果那么就直接返回之前的查询结果
- 如果匹配不到就执行完整的查询过程
查询缓存的条件限制
- 查询语句要严格匹配,MySQL Blog说是byte-for-byte match
- 使用临时表,用户变量,RAND(), NOW()和UDFs的查询直接不会使用查询缓存
- 查询缓存永远不会提供过时的结果集,意思就是MySQL会确保数据数据都是最新的。
- 对表的任何修改都会导致这张表所有的查询缓存失效(这个就有点逆天)
- 查询缓存和InnoDB MVVC集合到一起两个稍微有点冲突
我觉得有必要解释下第4条和第5条。
对表的任何修改都会导致这张表所有的查询缓存失效
查询缓存设计的初衷是加速查询过程。MySQL把SELECT语句和对应的结果集写入查询缓存,当下次相同的SQL发起时直接匹配查询缓存然后返回结果集,这样就省去了后续大量的查询处理过程。
给MySQL先点个赞。
但是因为要避免返回失效的数据,一旦对表的结构或者数据修改就要失效表的所有查询缓存。
那么下面这些操作都会让表查询缓存失效
- INSERT
- UPDATE
- DELETE
- ALTER
整体来说,MySQL设计查询缓存的初衷还是挺好的,但是这个失效粒度是不是稍微有点大,以表为最小失效粒度,而不是以行。
但是以行为失效粒度也可能会导致性能问题,因为数据表频繁变化,查询缓存要根据这些变化来不断地维护数据行,反而有可能导致查询缓存非但没有提升性能,反而导致性能问题。
查询缓存和InnoDB MVVC集合到一起两个稍微有点冲突
查询缓存和InnoDB MVVC结合其实确实会有冲突,因为InnoDB的事务隔离级别。
我们先来理解下MVVC。
多版本并发控制(MVCC)
MVCC是一种用于确保数据库事务在并发访问时读写操作互不干扰的机制。
它通过创建数据的一个快照(版本),让每个事务都在一个一致性的视图上工作,而无需直接锁定数据。因此,读操作不会阻塞写操作,反之亦然,这增强了并发处理的能力。
总的来说:数据库使用MVVC,在事务中这个数据在某个时间点和某个版本的数据保存到内存中作为快照,在整个事务期间对这个数据的查询都是使用内存中的这个快照。
InnoDB 和 MVCC
InnoDB是MySQL的默认存储引擎之一,它原生支持事务。利用MVCC,InnoDB允许读事务看到快照的数据版本,哪怕数据在其他并发事务中被修改。每个事务有其自己的“视图”,即数据的一致性状态,依赖于事务的隔离级别和开始时间。
查询缓存与MVCC
这句话提到了InnoDB存储引擎在使用查询缓存时需要遵循的一些限制,主要是要保证多版本并发控制(MVCC)的数据一致性。为了理解这一点,我们需要了解一些基础概念:
多版本并发控制(MVCC)
MVCC是一种用于确保数据库事务在并发访问时读写操作互不干扰的机制。它通过创建数据的一个快照(版本),让每个事务都在一个一致性的视图上工作,而无需直接锁定数据。因此,读操作不会阻塞写操作,反之亦然,这增强了并发处理的能力。
InnoDB 和 MVCC
InnoDB是支持事务的存储引擎,同时InnoDB在RD和RC两个事务隔离级别下使用MVVC。
使用MVVC就表示每个事务在执行期间对SELECT的数据都有一份自己的数据副本在内存中用来保证整个事务中的数据一致性状态。
查询缓存与MVCC
现在我们把InnoDB + MVVC + 查询缓存结合一下。
它们的冲突点就是InnoDB在RD和RC事务隔离级别下,多个不同的事务使用相同的SELECT语句会在内存中产生个不同的事务数据副本,那这个时候如果使用查询缓存来返回一个事务的查询,那么就可能会违反事务的隔离级别。
基于以上的原因,InnoDB的事务性读取可能不会从查询缓存中获取结果集,或者说很多时间查询缓存中的数据无法满足InnoDB对数据的需求。
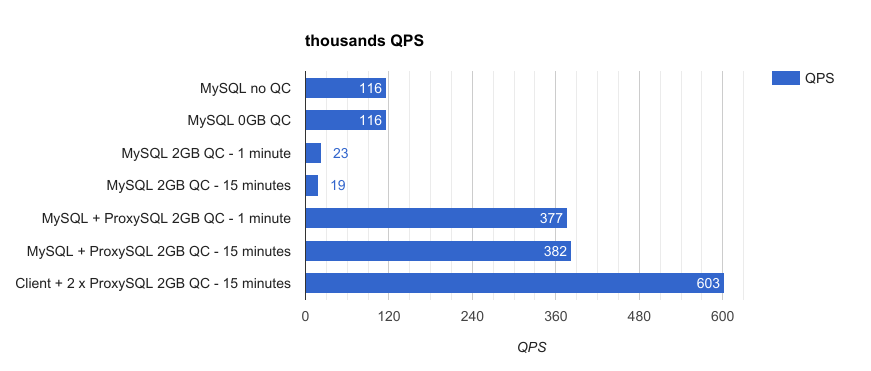
有查询缓存和无查询缓存的区别是什么?
MySQL在做出移除查询缓存这个决定之前还是做了很多的调研,它给出一张图来说明查询缓存的必要性和将查询缓存放到客户端更合适: