定义
霸道算法每次都会选出存活的进程中标识符最大的候选者作为协调者。
霸道算法之所以霸道是因为当有新的进程加入时,如果这个新进程是整个分布式系统进程标识符最大的进程那么它会决定自己是协调者,并向其他进程选举。即使当前有协调者进程正在正常工作,新进程也会替换掉老的协调者进程,这就是霸道算法的霸道点。
前提条件
- 霸道算法需要知道如何与整个分布式系统中所有进程通信。
- 霸道算法需要知道其他进程的标识符。
霸道算法假设进程间消息发送是可靠的,但是它允许在选举期间进程崩溃。
消息类型
霸道算法主要有三种消息类型:
- 选举消息: 用于宣布选举。
- 应答消息:用于回复选举。
- 协调者消息:用于宣布当选进程的协调者身份。
选举触发条件
-
当前协调者故障
故障检测器可以通过超时发现协调者已经出现故障,那么故障检测器就开始一次选举。 -
新的进程加入(老的进程从故障中恢复)
新的进程加入时发送一个选举消息
故障检测方式
基于超时机制。
客户端-服务端交互如下图:
那么一次交互完成的时间应该为消息请求发送时间(T2-T1)+消息处理时间(T3-T2)+消息应答发送时间(T4-T3),总时间为:T4-T1。基于总时间来设计一个超时机制检测故障。
算法流程
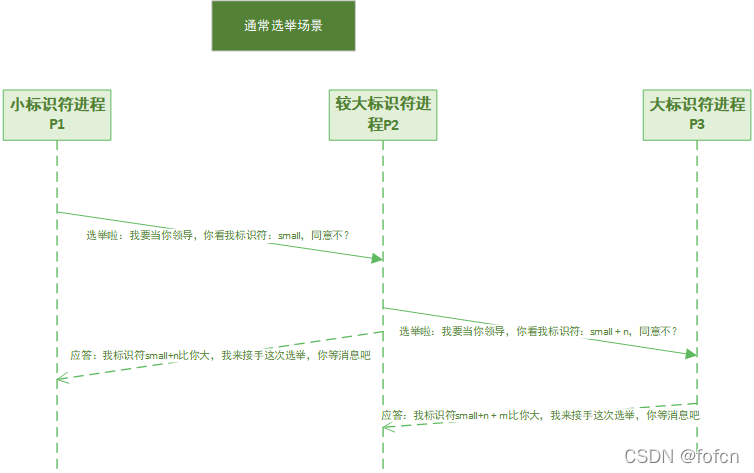
- 进程P向所有编号比它大的进程发送选举消息;
- 如果无人响应,P获胜并称为协调者;
- 如果编号比它大的进程响应,则由又想着接管选举工作,P的工作完成。
几个简单的时序图
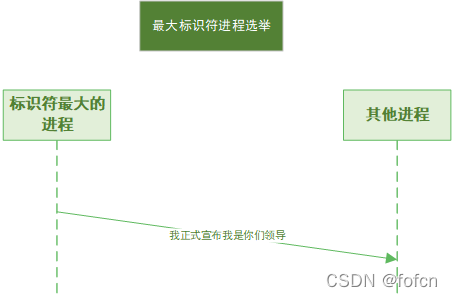
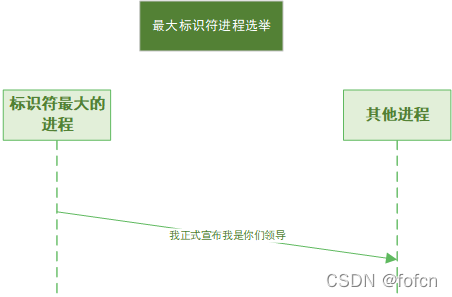
最大标识符进程选举
通常选举
算法分析
安全性
安全性是指参与选举的进程P要么没有选举要么已经选定了一个进程Q,Q是选举结束时具有最大标识符的非崩溃进程。
活性
活性是指所有参与选举的进程最终都知道了选举结果或者进程崩溃。
网络带宽
假设目前分布式系统中有N个进程:
-
最好情况
最好情况是在协调者故障后,目前正常运行的最大标识符进程立即检测到了协调者的故障立即选举自己并发送N-2个协调者消息给其他小标识符的进程。此时消息数量为θ(N) -
最坏情况
最坏情况是最小标识符的进程先检测到了协调者故障,然后从小到大依次检测到了协调者故障(N-1个进程),然后向其他N-2个进程发送选举消息,此时选举消息数量为(N-2) + (N-3) + … + 1 + 0为θ(N^2)个选举消息。
实现
简单情况
情况1:只有一个节点
启动后检查是否只有自己,如果只有自己那么就直接将自己设置为Leader。
情况2:有多个节点
启动后对大于自己的节点组播选举消息,等待应答;等待超时后如果没有应答则直接让自己成为Leader然后向其他人组播协调者消息。
情况3:霸道
启动后如果检查其他节点的标识符小于自己,则直接广播自己是Leader消息;当前的协调者收到后将自己Leader的角色放弃改为Follower。
情况4:协调者崩溃
Follower检测到Leader崩溃后,向比自己标识符大的节点发送选举消息。
单点与集群图

算法
/**
* 霸道选举算法
* 流程节点
* 1. 配置加载与解析
* 2. 发起选举
* 2.1 if 集群中只有自己一个节点,
* then 直接选择自己为Coordinator;
* 2.2 else
* if 如果自己的选举标识符比所有的都大,
* then 直接向所有的节点发送协调者消息;
* else
* 向所有大于自己选举标识符的节点发送选举消息,等待响应;
* if 等待超时后没有节点回复,
* then 直接选举自己为协调者并向所有的节点发送协调者消息
* else
* 等待协调者消息;
* if 收到协调者消息
* then 设置协调者并将自己设置为follower
* else 进入2.2循环
*
* endif
* 3. 故障检测
* 3.1 定时与协调者发起心跳消息进行故障检测
* 在3T时间内(实现为3次吧,每次T秒钟超时时间)没有响应则认为协调者故障
* 算法:
* send 心跳消息,等待协调者回复
* if 心跳消息超时,故障计数+1
* if 故障计数 >=3:协调者故障
* 发起选举;
* else
* 等待下次定时器调用
* else
* 收到了服务;
* 故障计数清零;
*
*
* @author errorfatal89@gmail.com
* @date 2022/03/09
*/代码实现
我简单实现了一版本霸道选举算法,代码地址:霸道选举算法
参考
- 维基百科:霸道选举算法
- 分布式系统概念与设计(原书第五版)
- 分布式系统原理与范型(第二版)