概述
Cache Aside是一种常用的缓存策略,也被称为"旁路缓存"。
工作原理
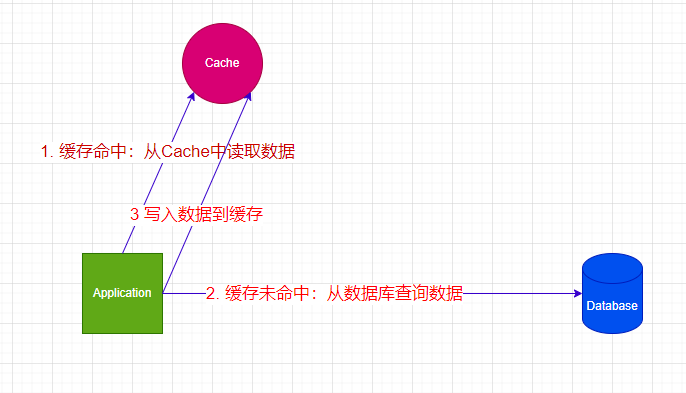
- 读操作:当应用程序需要读取某些数据时,它首先会检查缓存中是否有这些数据。如果缓存中有这些数据(缓存命中),它就直接返回这些数据。否则,它会从数据源(如数据库)中读取这些数据,并在返回数据之前先将数据放入缓存中。
- 写操作:当应用程序需要写入某些数据时,它首先会将这些数据写入数据源,然后让缓存在缓存中对应的条目失效(if it exists)。
优点(Pros)
- 简单直观: Cache Aside策略非常直观和容易实现。它不需要复杂的策略或者算法。
- 数据一致性:由于每次写操作都会使缓存失效,所以在写入后的读操作不会读到过时的数据,保证了一致性。
缺点(Cons)
- 两次访问操作:在缓存未命中的情况下,Cache Aside策略需要两次访问操作:一次是应用程序从数据源读取数据,另一次是将数据放入缓存。
- 脏读:如果某个节点上的缓存未命中,并去数据库中读取数据,这个时候另一个节点刚好更新了数据并且新的数据还未来得及同步到这个节点的缓存中,那么该节点读取到的还是旧数据。
- 缓存雪崩问题: 如果缓存服务器重启或者是出现了大面积的缓存失效,应用程序之后的数据都需要到数据源读取,可能导致数据源压力过大甚至崩溃,这就是通常说的缓存雪崩问题。
分析
我们来自己分析下Cache Aside缓存策略。
当然,我们需要结合应用的生命周期来分析,这样才知道Cache Aside策略需要解决的一些问题。
启动阶段
当我们启用我们的应用服务时,我们的Cache是空的,数据库可能会有数据。这时候所有的流量都是未命中缓存(Cache Miss)而直接查询数据库,这可能导致启动初期一段时间能应用性能低(数据库负载高,一不小心应用崩溃了,二不小心数据库崩溃了)。
为了解决这个问题,一般的策略是在应用启动时对缓存进行预热(prewarming/bulkloading)。
预加载哪些数据到缓存中?一般是根据业务情况加载一些常用的数据到缓存中。比如:比较好卖的东西,用户喜欢看的东西。
没有那么大量不用预热,还得写代码还得测试收入收入比不高。如果你想练技术就另当别论了。
怎么预热?
- 确定预热数据(需求方反馈,日志分析,统计来得到热点数据)
- 预热策略选择(这个根据实际情况自己来选择:系统启动,定时任务和手动)
- 控制预热速度(分批处理,限制并发)
- 预热验证(性能测试)
- 迭代更新(你每加一个东西进你的服务,在每个迭代可能都得考虑它,因为下个迭代的时候之前的数据可能就会被废弃了,你得维护它)
用什么框架预热?有预热框架的用预热框架,没有的直接手写预热,实在不行让测试大哥大姐们写脚本调用接口预热。
运行阶段
运行阶段:在应用运行期间,主要需要解决的问题是保持缓存数据和数据库数据的一致性。在写操作后,需要使缓存中对应的数据失效,以防止后续的读操作获取到旧的数据。同时,为了防止缓存雪崩,可以使用一些策略,比如缓存数据的过期时间进行随机,使得不会有大量的数据同时过期。
整体上我们需要预防以下内容:
- 缓存一致性
- 避免旧数据
- 防止缓存雪崩
- 缓存穿透
缓存一致性
缓存一致性的方案主要有:
- 先更新数据库再删除缓存
- 先删除缓存在更新数据库
- 先删除缓存,然后更新数据库,最后再删除缓存
一般我们会使用先更新数据再删除缓存这个方案,因为第2个方案在读写并发时会出现缓存和数据库数据不一致的情况。
至于最后的一次删除是在业务代码中直接同步删除还是MQ删除根据你的业务情况来确定。
缓存雪崩
为了避免大量的数据在同一时间点过期造成的缓存雪崩,可以使用一些策略,如将缓存数据的过期时间做随机处理,使得数据不会集中在同一时刻过期。
- 大量缓存在同一时间过期
- 缓存宕机
- 大流量导致缓存无法承载
缓存穿透
缓存穿透是请求的数据不在缓存中需要到数据库中查询导致数据库负载过高。
缓存穿透的原因:
- 代码Bug:有Bug是经常的事
- 设计问题:用户感兴趣的数据没有缓存策略
- 数据尚未缓存:缓存中就是没有,因为预热没有这个数据,用户也从来没有请求过这个数据
- 缓存空间满了:缓存满了,缓存系统要不停的替换掉旧的缓存,颠簸现象
- 缓存数据正在写入缓存系统:数据正在写入缓存系统,但是在此期间依然有大量查询该缓存的请求
- 自己把缓存删除了,因为业务需求
扩展阶段
随着应用的增长,数据量可能会增大,这可能导致缓存容量不足。这时就需要进行缓存的扩容,可能需要选择一个可扩展的缓存系统,比如redis分布式缓存。同时,为了防止热点数据导致的缓存击穿,可以对热点数据进行特殊处理,比如增加副本。
关闭阶段
在应用关闭时,需要考虑缓存数据的持久化问题,以防止应用重启后缓存数据全部丢失,导致缓存未命中率大增。这需要选择支持持久化的缓存系统,或者再重新加载数据到缓存中。