介绍
本文介绍了如何使用 Apache Flink 进行 MySQL 数据库之间的实时数据同步。我们将了解 Flink 如何与 MySQL 连接,如何实现实时数据流的处理与传输,以及如何维护数据的一致性。
在许多业务场景中,我们需要在分布式环境下对 MySQL 数据库进行实时数据同步。例如,我们可能需要将生产环境的数据库同步到测试环境以便进行测试。另一个典型的场景是数据分析,我们可能需要将数据同步到离线分析环境或者实时分析环境。传统的方法是通过定时任务或者批处理任务进行数据同步,但这种方法往往无法满足实时处理的需求。本文将介绍如何使用 Apache Flink 实现 MySQL 之间的实时数据同步。
Apache Flink简介
Apache Flink是一个开源的大数据处理框架,支持批处理和流处理,具有高吞吐量、低延迟的特点。Flink 提供了多种数据源和数据流 API,可以与各种数据存储系统进行集成。Flink 的严格的事件驱动处理模型使其特别适用于实时数据同步。
实现过程
以下内容是使用Apache Flink实现MySQL之间实时数据同步的关键步骤:
1. 准备环境
首先我们需要准备Flink的运行环境,我们这儿使用docker-compose的方式来启动Flink。然后我们再准备两个MySQL数据库,源数据库和目标数据库用于进行表与表之间的数据同步。
1.1. Flink环境启动
我们这里使用Flink 1.15,目前最新稳定版本为1.17,docker compose yaml文件可以参考本站链接:Apache Flink Docker compose 启动,如果你的电脑和我一样是Windows可以安装Docker Destop,安装完成后如果没有docker-compose命令可以安装一个Windows的docker-compose命令。
1.2. 两个MySQL数据库启动
我们这里选择使用docker compose方式启动,数据库版本为MySQL 8, docker compose yaml文件内容如下:
version: "2.2"
services:
mysql8-source:
image: mysql:8.0
container_name: mysql-source
command: --default-authentication-plugin=mysql_native_password
restart: always
environment:
MYSQL_ROOT_PASSWORD: your_root_password
MYSQL_DATABASE: your_db_name
MYSQL_USER: your_username
MYSQL_PASSWORD: your_user_password
ports:
- "3306:3306"
volumes:
- ./my.cnf:/etc/mysql/my.cnf
mysql8-sink:
image: mysql:8.0
container_name: mysql-sink
command: --default-authentication-plugin=mysql_native_password
restart: always
environment:
MYSQL_ROOT_PASSWORD: your_root_password
MYSQL_DATABASE: your_db_name
MYSQL_USER: your_username
MYSQL_PASSWORD: your_user_password
ports:
- "3307:3306"
volumes:
- ./my.cnf:/etc/mysql/my.cnfyaml文件中有引用本地的MySQL配置文件my.cnf,该文件是为了配置MySQL binlog,文件内容如下:
[mysqld]
server-id = 1
log_bin = mysql-bin
binlog_format = ROW
binlog_row_image = FULL
expire_logs_days = 101.3. 生成Flink Maven工程
首先需要安装JDK 11,然后安装Apache Maven 3,安装配置完成后强烈建议使用Apache Flink的Maven archetype来生成Flink 工程,因为很多依赖需要设置scope为provided,这些依赖如果自己摸索可能会踩很多坑。使用mvn命令生成Flink代码工程(版本号我这儿选择的是1.15.4,你可以根据自己的需要选择正确的版本号)
mvn archetype:generate -DarchetypeGroupId=fofcn.tech.flink -DarchetypeArtifactId=flink-db-sync -DarchetypeVersion=1.15.4工程生成后可以使用IDE打开进行开发。
2. 基于SQL/Table API实现数据同步
以下内容是基于Apache Flink SQL/Table API实现数据的关键步骤:
2.1 源和目标数据库和表结构准备
我们以同步一个系统用户数据为例,首先创建数据库和数据表, SQL如下:
CREATE DATABASE `flink_test`;
USE `flink_test`;
CREATE TABLE `sys_user`(
id BIGINT PRIMARY KEY,
username varchar(64) NOT NULL,
age int,
nickname varchar(64) DEFAULT '',
create_time date NOT NULL,
modified_time date
)COMMENT 'user';这个SQL在两个数据库中都执行。
2.2. 编写source,sink SQL和同步SQL
这里的localhost需要替换为你电脑网卡的IP或者docker的服务名,否则在容器内无法连接MySQL数据库。
源SQL
CREATE TABLE user_source (
id BIGINT PRIMARY KEY,
username STRING,
nickname STRING,
age INT,
create_time DATE,
modified_time DATE
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = 'your_root_password',
'database-name' = 'flink_test',
'table-name' = 'sys_user'
);目标SQL:
CREATE TABLE user_sink (
id BIGINT PRIMARY KEY,
username varchar(60),
nickname varchar(60),
age INT,
create_time DATE,
modified_time DATE
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3307/flink_test',
'username' = 'root',
'password' = 'your_root_password',
'table-name' = 'sys_user'
);同步逻辑SQL:
INSERT INTO `user_sink` SELECT * FROM `user_source`2.3. 创建Flink Stream环境并执行SQL
// Flink Stream Env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000));
EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);
// source
String sourceSQL = SQLReaderUtil.readSQL(SOURCE_TABLE_NAME);
log.info(sourceSQL);
tableEnv.executeSql(sourceSQL);
// sink
String sinkSQL = SQLReaderUtil.readSQL(SINK_TABLE_NAME);
log.info(sinkSQL);
tableEnv.executeSql(sinkSQL);
// INSERT SQL
String insertSQL = SQLReaderUtil.readSQL(INSERT_SQL_NAME);
log.info(insertSQL);
StatementSet statementSet = tableEnv.createStatementSet();
statementSet.addInsertSql(insertSQL);
statementSet.execute();
Jar包SQL文件内容读取工具类代码 SQLReaderUtil:
import java.io.BufferedInputStream;
import java.io.IOException;
import java.io.InputStream;
public class SQLReaderUtil {
public static String readSQL(String filename) {
try (InputStream inputStream = SQLReaderUtil.class.getResourceAsStream("/sql/" + filename)) {
BufferedInputStream bufferedInputStream = new BufferedInputStream(inputStream);
byte[] fileContent = bufferedInputStream.readAllBytes();
return new String(fileContent);
} catch (IOException e) {
throw new RuntimeException(e);
}
}2.4. 打包为jar上传到Flink并执行
mvn clean package上传到Flink,首先打开Flink web页面:http://localhost:8081/, 然后点击Submit New Job–> Add New, 截图如下:
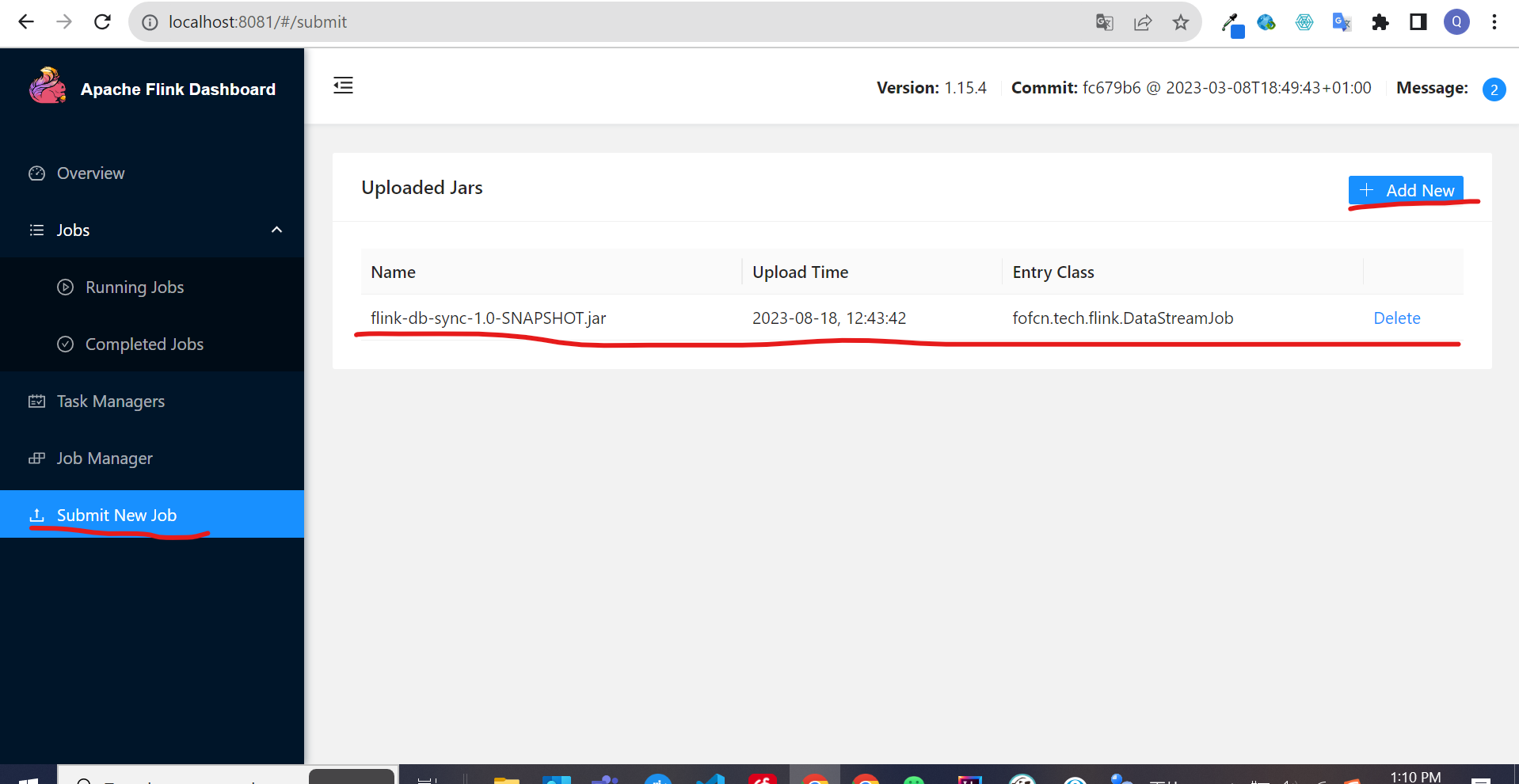
Jar包提交成功后点击flink-db-sync-1.0-SNAPSHOT.jar这一行,点击后会出现如下截图内容:

点击 Submit 按钮即可。如果点击后有错误提示,可以点击 Job Manager进行查看日志,如下截图:

如果 Submit后没有任何报错就会进入Running Jobs界面,任务开始执行,因为使用的是流模式,所以该任务不会停止而是会一直执行,如下截图:

总结
本文介绍了如何使用 Apache Flink 实现 MySQL 数据库之间的实时数据同步。利用 Flink 的实时处理功能和灵活的数据流 API,可以轻松地在多个 MySQL 数据库之间同步数据。在实际生产环境中,我们还需要考虑异常处理、任务重启和监控等问题,以确保系统的稳定性和可靠性。