1、简介
raft一致性算法基于Pasox算法,但是更容易理解和实现。
raft集群一般要有几个节点实例:通常是5个节点实例,因为这样可以允许2个节点故障而不影响可用性(因为选举算法需要N/2 + 1个同意票才可以选举成功)。
2、Paxos的问题
- 难以理解
大家对Paxos论都感到很疑惑,基于自己的理解各执一词,那这样的话大家就无法进行统一和制定标准(感觉这也是一个分布式问题啊,这得出现一个Paxos Leader角色,一言堂搞定所有人的说辞,但是你懂的总有不服你的)。 - 难以实现
Paxos协议我没有读过,只能复制“Diego Ongaro and John Ousterhout”两神的说法: its architecture requires complex changes to support practical systems.
3、raft
raft算法分为三个步骤:
- Leader选举
- 日志复制
- 安全性
4、特性
-
强大的Leader
日志节点只能从Leader分发到其他成员服务器,这样做的目的简化了管理和更容易理解。 -
Leader选举
raft使用了随机时间的定时器来选举领导者。 -
成员变更
raft使用共同共识方法来处理成员变更问题,这样在选举期间依然可以对外提供服务。
5、Leader选举
集群中每个节点的状态有三种,分别为Leader、Follwer和Candidate。
5.1、领导人状态:Leader
集群中只有一个节点为Leader,剩余节点都为Follower。Leader处理所有的客户端请求。如果有客户端连接了Follower,那么Follower会将客户端重定向到Leader。
5.2、跟随者状态:Follower
Follower是被动的:他们一般都是被动响应Leader或者Candidate的请求。
5.3、候选人状态:Candidate
Candidate只有在选举Leader时才会出现。一般集群初始化时没有Leader需要选举处一个Leader,或当前Leader故障时才会转换到此状态。
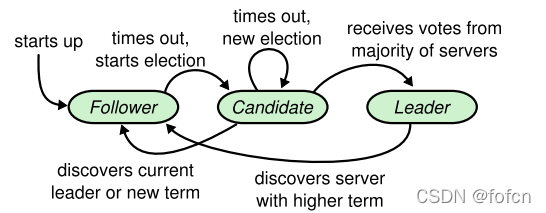
5.4、三种状态转换(论文版本)
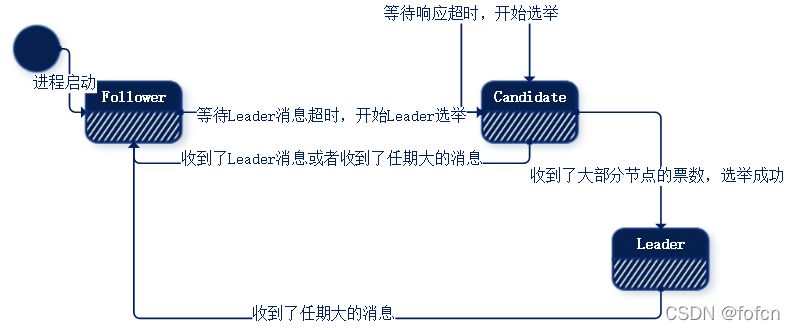
5.5、三种状态转换(手画版本)
5.6、状态转换说明
所有的raft节点启动的时候,所有节点都是Follower状态,那么这些所有的Follower状态的节点都在等待Leader的消息,在等了一个超时时间内没有收到Leader消息,说明集群中还没有Leader或者集群中的Leader故障了。
没有收到Leader消息的Follower将状态转换为Candidate并开始选举。
5.6.1、Follower
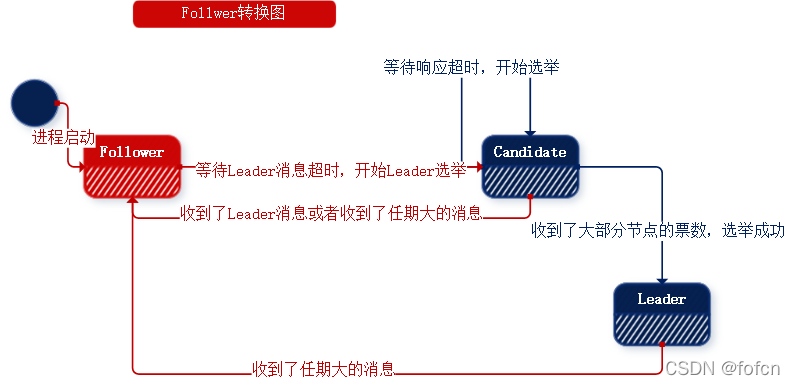
-
集群中所有节点启动,默认为Follower状态;
在集群节点启动的时候,新启动的节点处于Follower状态,新节点会等待一个固定超时时间的Leader消息,如果在这个固定超时时间内没有等到Leader消息,那么新节点就发起一次选举,并将自己的状态转换为Candidate状态。 -
Follower状态等待Leader心跳消息,等待Leader消息超时就开始选举并进入Candidite状态;
5.6.2、Candidate
- Candidate等待投票消息超时再次发起新一轮的选举;
- Candidate获得了大多数服务节点的票数(N/2+1,其中N为集群节点数)后转换为Leader;
- Candidate收到了Leader消息或者新任期时转换为Follower等待Leader消息;
5.6.3、Leader
- Leader状态在收到了任期大节点的消息后转换为Follower状态;
5.7、 日志复制
Leader从客户端接收日志然后复制到集群中的Follower节点,并且强制要求Follower节点的日志保持和自己的相同。
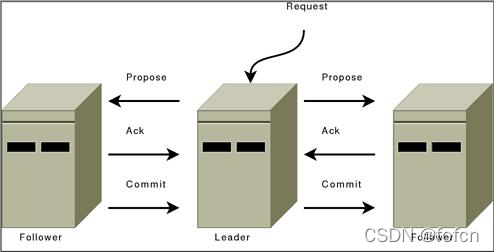
5.7.1、复制状态机
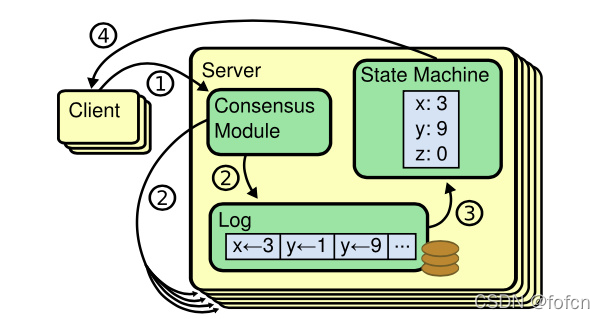
现在可以看到的Server是Leader角色,Server下面的是Followers。
图中1、2、3和4步骤如下:
- 客户端请求Leader服务器,请求信息就是一系列的指令;
- Leader在收到请求以后,将操作同步到所有的Follower服务器中(包括自己);
- Leader和Follower服务器收到同步的指令以后,就将请求应用到状态机中;
- 最后响应结果给客户端。
5.7.2、顺序
Leader按照客户端的指令顺序来同步到所有的Follower中,同步中不能打乱顺序也不能丢失请求,否则状态机的状态会不一致。
5.7.3、ZAB协议中的同步
5.8、安全性
分布式中选举安全性是指经过几轮选举以后一定可以选出一个Leader,并且选出来的Leader一定是活的没有故障的节点。raft协议安全性还要求已经应用到集群中的状态不能丢失,raft保证状态不丢弃的方式是候选人的状态日志必须是最新的。
raft协议满足非拜占庭条件下的安全,包括网络延迟、分区、丢包、重复和重排序。
5.8.1、选举限制
raft的选举机制保证被选举出来的Leader包含所有提交的日志节点。
如果一个Candidate相对于其他所有Candidate的日志节点是最新的,那么就认为这个Candidate节点拥有所有已提交的日志节点。
raft通过投票RPC中包含Candidate的日志信息来拒绝投票给其他日志少的Candidate票。
5.8.2、日志覆盖
raft保证Leader只能提交当前任期的日志,不能提交之前任期的日志。
来看张图(提交之前任期的日志导致日志被覆盖):
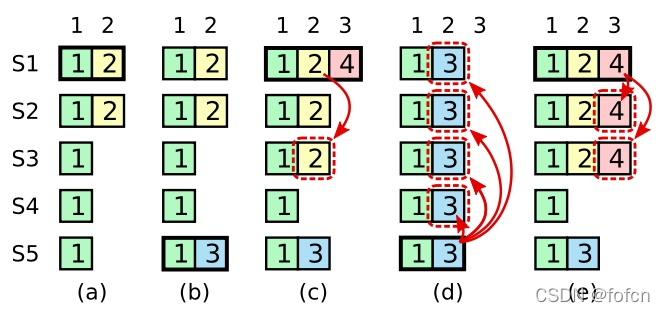
有5个服务节点S1-S5,abcde为时序:a<b<c<d&e
- 在时序a,节点S1是Leader,在S1服务期间接收了请求2并将其传播到S2后崩溃;
- 在时序b,节点S5当选了Leader并且处理了请求3并将3放到日志节点2的位置后崩溃;
- 在时序c,节点S1再次当选为Leader,然后继续复制日志节点2到其他大部分服务器但未提交,然后崩溃;
- 在时序d,节点S5再次当选为Leader,然后使用日志节点2的数据项3覆盖了所有的节点;
- 在时序e,如果S1将日志节点2的数据项2复制到了大部分服务节点并进行了提交,那么S5就不会当选为Leader。