What is SQL?
SQL (Structured Query Language) is a domain-specific language used in programming for managing data held in a Relational Database Management System (RDBMS), or stream processing in a relational data stream management system (RDSMS).
- How to pronounce SQL? Two types of pronunciation: reading by letter or reading as a whole. Pronunciation by letter is /ˌɛsˌkjuːˈɛl/, while continuous reading is /ˈsiːkwəl/.
What is a relational database?
A relational database is a type of database where data is stored and provided in relation to each other. Relational databases are organized through a relational model. The relationship is usually organized in rows and columns across multiple tables. Rows in the table are also called records or tuples. Columns are also referred to as properties.
What is a database?
A database is a collection designed to organize, store, and manage data according to a data model. Databases are generally made up of many tables that are directly or indirectly related to each other. We can define the table as a node in the graph, and the relationship as the edge between them. As shown in the figure below:
What is a Database Management System (DBMS)?
The database management system is the core part of the database system. It is responsible for all CRUD operations. Without it, there would be no database system.
Common Database Management Systems: MySQL, PostgreSQL, MariaDB, Oracle, SQL Server, DB2… and many more.
What is a Database System?
A database system is an ecological system that includes databases, database management systems, integrated database environments, and your applications (we are all database system engineers…). This means that you first need a system for CRUD operations on your database. Then you need various drivers to connect to the database system, or have a GUI client to operate the database.
For example, when you start a MySQL server, you are starting a database management system. When you create your own database in MySQL and use MySQL’s drivers and dialects to operate the MySQL database, all these operations collectively form the database system.
What is the Relational Data Stream Management System?
The relational data stream management system is a system that emulates some concepts and techniques of the database management system to quickly respond to a large amount of streaming data. In my understanding, this covers the area of big data.
Common relational data stream management systems: Spark, Flink, Storm.
All SQL referenced in this article is based on the MySQL 8.0 database system.
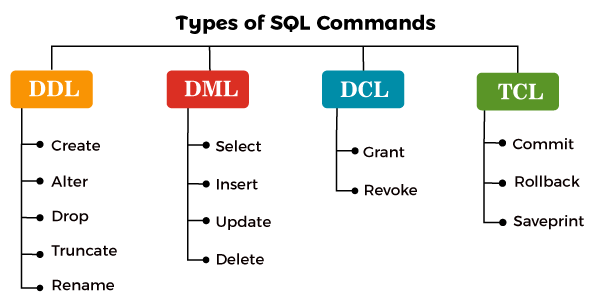
DDL, DQL, DCL, and DML
These concepts are complicated.
- DDL (Data Definition Language)
- DQL (Data Query Language): used to query data in data, specifically refers to SELECT
- DCL (Data Control Language): used for permission control: Authorization
- DML (Data Manipulation Language): refers to CRUD operations
- TCL (Transaction Control Language): used for transaction management in db
DQL is not widely accepted. We often hear more about DDL, DML, and DCL. I understand this is because SELECT is specifically for SELECT xxxx. If you use FROM and WHERE, then FROM and WHERE belong to DML, which seems kind of redundant.
Constraints
Constraints are a way to limit data to a certain range. For example, if you limit a user’s username to not exceed 20 Chinese characters, and limit the gender type in the database to only numerical values, the database will abide by these constraints. When the program writes more than 20 Chinese characters into the username, it will throw an error. Similarly, an error will be thrown when writing a string into the gender field.
Of course, our demand for constraints is quite high, mainly including the following types:
- Primary key
- Unique key
- Foreign key
- Check
- NOT NULL
- Default
- Data type
- Field length
We have listed so many above. MySQL can use the following SQL queries:
SELECT * FROM information_schema.table_constraints;Data Types
The database provides many data types to meet our application needs. Although there are many, it is clear after classification. Check the data type chart:
common used data types
Numberic Types
| Numeric Type | Signed Range | Unsigned Range |
|---|---|---|
| TINYINT | -128 to 127 | 0 to 255 |
| SMALLINT | -32768 to 32767 | 0 to 65535 |
| MEDIUMINT | -8388608 to 8388607 | 0 to 16777215 |
| INT or INTEGER | -2147483648 to 2147483647 | 0 to 4294967295 |
| BIGINT | -9223372036854775808 to 9223372036854775807 | 0 to 18446744073709551615 |
| DECIMAL (M,D) or NUMERIC (M,D) | Depends on M and D values | Depends on M and D values |
| FLOAT (P) | -3.402823466E+38 to -1.175494351E-38, 0, and 1.175494351E-38 to 3.402823466E+38 | 0 to 3.402823466E+38 |
| DOUBLE (M,D) | -1.7976931348623157E+308 to -2.2250738585072014E-308, 0, and 2.2250738585072014E-308 to 1.7976931348623157E+308 | 0 to 1.7976931348623157E+308 |
| BIT (M) | -2^(M-1) to 2^(M-1)-1 | 0 to 2^M-1 |
| BOOLEAN | N/A | N/A |
| SERIAL | N/A | 1 to 18446744073709551615 |
What is the size of column of int(11) in mysql in bytes?
String types
| String Type | Description |
|---|---|
| CHAR(M) | A fixed-length string useful when all values are approximately the same length. Pad with space when saved. M can be from 0 to 255. |
| VARCHAR(M) | A variable-length string useful when values are of varying length. M can be from 0 to 65535. |
| TINYTEXT | A tiny text string holding a maximum length of 255 characters. |
| TEXT | A text string holding a maximum length of 65,535 characters |
| MEDIUMTEXT | A medium-sized text string which can hold a string with a maximum length of 16,777,215 characters |
| LONGTEXT | A large text string which can hold a string with a maximum length of 4,294,967,295 characters |
| ENUM(‘value1′,’value2’,…) | A string object with a value chosen from a list of permitted values |
| SET(‘value1′,’value2’,…) | A string objects that can have zero or more values, each of which must be chosen from a list of permitted values |
| BINARY(M) | Similar to CHAR, but stores binary byte strings. Pad with 0x00 bytes when saved. |
| VARBINARY(M) | Similar to VARCHAR, but stores binary byte strings. |
| TINYBLOB | A binary large object column with a maximum length of 255 bytes |
| BLOB | A binary large object column with a maximum length of 65,535 bytes |
| MEDIUMBLOB | A binary large object column with a maximum length of 16,777,215 bytes |
| LONGBLOB | A binary large object column with a maximum length of 4,294,967,295 bytes |
Date types
| Date/Time Type | Description |
|---|---|
| DATE | A date. The supported range is ‘1000-01-01’ to ‘9999-12-31’. |
| DATETIME | A date and time combination. The supported range is ‘1000-01-01 00:00:00’ to ‘9999-12-31 23:59:59’. |
| TIMESTAMP | A timestamp. The range is ‘1970-01-01 00:00:01’ UTC to ‘2038-01-19 03:14:07’ UTC. |
| TIME | A time. The range is ‘-838:59:59’ to ‘838:59:59’. |
| YEAR | A year in four-digit format. Values in the range 1901 to 2155 and 0000. |
how to choose?
There are so many data types for us to choose from.
How to choose? Generally, based on our business needs, and in order to meet a certain degree of scalability, choose the type with the smaller storage size. Small storage types take up less cpu, memory and disk space, and the data stored in a data leaf is more, resulting in fewer increases, deletions, checks, and changes in I/O operations.
Character Sets and Collation
Character sets (Character Set) and collation (Collation) are important concepts related to character encoding and string comparison.
Character Set: A character set is a set of symbols. In a computer, each symbol is represented by a number of bits, and each symbol corresponds to a unique bit pattern. Simply put, the character set is the correspondence between a symbol and a bit pattern.
In MySQL, it supports multiple character sets, such as utf8 (use 1 to 3 bytes to store characters), utf8mb4 (use 1 to 4 bytes to store characters), latin1 (use 1 byte to store characters), etc. Choosing the right character set can ensure that your database correctly stores and displays textual content in various languages.
Collation: The collation determines the comparison rules between strings. For example, in English, the letters "a" and "A" are the same. But in the computer, the ASCII code of "a" is 97, and the ASCII code of "A" is 65, which are different in the computer’s view. Therefore, we need a rule to guide the computer on how to handle this situation when comparing, this rule is the so-called collation.
Different languages and regions have different collation rules.
But I have never modified the collation rules. I only changed the utf-8 character set to utf8mb4 in order to store emoji expressions.
Pitfalls for Collations
insert into trade_user (name, email, age, birthday, created_at, updated_at) values ('FOFCN.TECH', 'fofcn@fofcn.tech', NULL, now(), now(), now());
Query OK, 1 row affected (0.01 sec)
mysql> select * from trade_user where name='fofcn.tech';
+--------+------------+------------------+------+---------------------+---------------------+---------------------+
| id | name | email | age | birthday | created_at | updated_at |
+--------+------------+------------------+------+---------------------+---------------------+---------------------+
| 525591 | fofcn.tech | fofcn@fofcn.tech | 35 | 1989-05-25 00:00:00 | 2024-04-10 09:30:12 | 2024-04-10 09:30:12 |
| 525592 | fofcn.tech | fofcn@fofcn.tech | NULL | 1989-05-25 00:00:00 | 2024-04-10 09:31:24 | 2024-04-10 09:31:24 |
| 525593 | FOFCN.TECH | fofcn@fofcn.tech | NULL | 2024-04-11 09:39:32 | 2024-04-11 09:39:32 | 2024-04-11 09:39:32 |
+--------+------------+------------------+------+---------------------+---------------------+---------------------+
3 rows in set (0.00 sec)What? FOFCN.TECH maybe an unexpected row for my query. what’s happened?
SELECT DEFAULT_COLLATION_NAME
FROM INFORMATION_SCHEMA.SCHEMATA
WHERE SCHEMA_NAME = 'trade_order';
+------------------------+
| DEFAULT_COLLATION_NAME |
+------------------------+
| utf8mb4_0900_ai_ci |
+------------------------+
SELECT TABLE_COLLATION
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'trade_order'
AND TABLE_NAME = 'trade_user';
+--------------------+
| TABLE_COLLATION |
+--------------------+
| utf8mb4_0900_ai_ci |
+--------------------+
SELECT COLUMN_NAME, COLLATION_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = 'trade_order'
AND TABLE_NAME = 'trade_user'
AND COLUMN_NAME = 'name';
+-------------+--------------------+
| COLUMN_NAME | COLLATION_NAME |
+-------------+--------------------+
| name | utf8mb4_0900_ai_ci |
+-------------+--------------------+
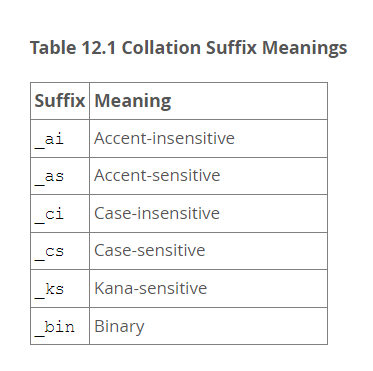
12.3.1 Collation Naming Conventions
OK, change to cs.
-- To change the collation of a database
ALTER DATABASE trade_order COLLATE utf8mb4_general_cs;
-- To change the collation of a table
ALTER TABLE trade_user CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_general_cs;
-- To change the collation of a column
ALTER TABLE trade_user CHANGE name name varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_cs;
DDL Statement
The DDL statement helps us to build a database from scratch.
Database CRUD
Create a database
First, we need to create a database. The syntax for creating a database in MySQL is as follows:
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name
[create_option] ...
create_option: [DEFAULT] {
CHARACTER SET [=] charset_name
| COLLATE [=] collation_name
| ENCRYPTION [=] {'Y' | 'N'}
}Modify a database
MySQL ALTER DATABASE cannot modify the database name, as can be seen from its alter_option.
ALTER {DATABASE | SCHEMA} [db_name]
alter_option ...
alter_option: {
[DEFAULT] CHARACTER SET [=] charset_name
| [DEFAULT] COLLATE [=] collation_name
| [DEFAULT] ENCRYPTION [=] {'Y' | 'N'}
| READ ONLY [=] {DEFAULT | 0 | 1}
}Delete a database
The SQL statement for deleting a database is very simple, but it is a high-risk operation. Many people may lose their jobs because of this SQL.
DROP {DATABASE | SCHEMA} [IF EXISTS] db_nameQuery a database
MySQL has multiple ways to query databases:
- show
- data dictionary
-- show query database
SHOW DATABASES;
SHOW DATABASES like '%trade%';
-- data dictionary query database
SELECT `SCHEMA_NAME`
FROM `INFORMATION_SCHEMA`.`SCHEMATA`;
SELECT `SCHEMA_NAME`
FROM `INFORMATION_SCHEMA`.`SCHEMATA` WHERE SCHEMA_NAME LIKE '%trade%';Create a table
The SQL for creating a table in MySQL is particularly long. We only provide a part of it here. You usually use a tool to generate it yourself:
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
(create_definition,...)
[table_options]
[partition_options]
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
[(create_definition,...)]
[table_options]
[partition_options]
[IGNORE | REPLACE]
[AS] query_expression
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
{ LIKE old_tbl_name | (LIKE old_tbl_name) }
create_definition: {
col_name column_definition
| {INDEX | KEY} [index_name] [index_type] (key_part,...)
[index_option] ...
| {FULLTEXT | SPATIAL} [INDEX | KEY] [index_name] (key_part,...)
[index_option] ...
| [CONSTRAINT [symbol]] PRIMARY KEY
[index_type] (key_part,...)
[index_option] ...
| [CONSTRAINT [symbol]] UNIQUE [INDEX | KEY]
[index_name] [index_type] (key_part,...)
[index_option] ...
| [CONSTRAINT [symbol]] FOREIGN KEY
[index_name] (col_name,...)
reference_definition
| check_constraint_definition
}
Here gives an example, creating a trade_user table, this table has the following fields:
+------------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+------------------+------+-----+---------+----------------+
| id | bigint unsigned | NO | PRI | NULL | auto_increment |
| name | varchar(20) | NO | MUL | NULL | |
| email | longtext | YES | | NULL | |
| age | tinyint unsigned | YES | | NULL | |
| birthday | datetime | YES | | NULL | |
| created_at | datetime | YES | | NULL | |
| updated_at | datetime | YES | | NULL | |
+------------+------------------+------+-----+---------+----------------+
The corresponding create table statement is as follows:
CREATE TABLE trade_user (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
email LONGTEXT,
age TINYINT UNSIGNED,
birthday DATETIME,
created_at DATETIME,
updated_at DATETIME,
PRIMARY KEY (id),
INDEX idx_name (name)
);
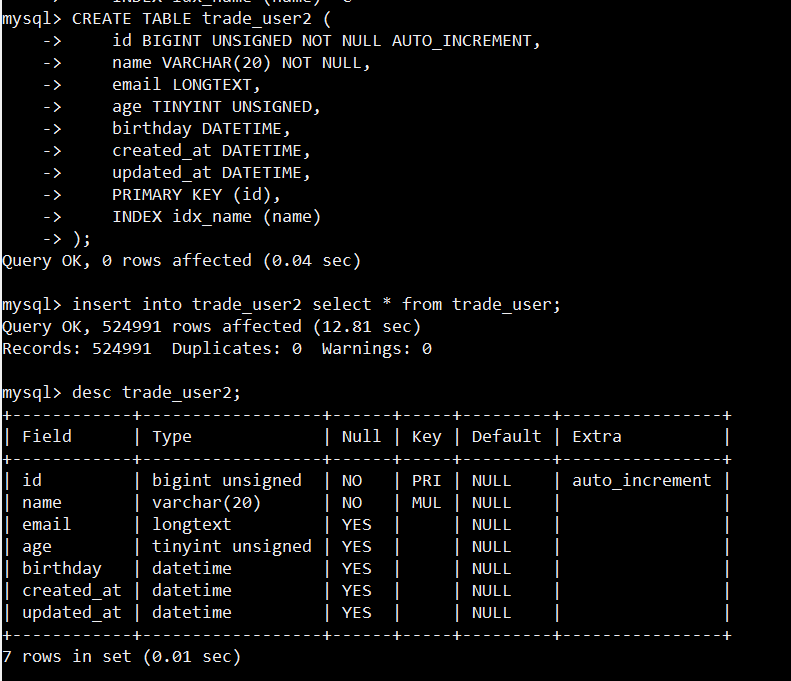
Let’s create another trade_order table to represent the user’s order. It will be more convenient for us to test join SQL later.
The table structure is shown below:
+--------------+-----------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-----------------+------+-----+---------+----------------+
| id | bigint unsigned | NO | PRI | NULL | auto_increment |
| user_id | bigint unsigned | YES | | NULL | |
| order_no | bigint unsigned | YES | | NULL | |
| created_at | datetime | YES | | NULL | |
| updated_at | datetime | YES | | NULL | |
| total_amount | bigint unsigned | YES | | NULL | |
| paied_amount | bigint unsigned | YES | | NULL | |
+--------------+-----------------+------+-----+---------+----------------+
The create table SQL:
CREATE TABLE trade_order (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
user_id BIGINT UNSIGNED NOT NULL,
order_no BIGINT UNSIGNED NOT NULL,
created_at DATETIME NOT NULL,
updated_at DATETIME NOT NULL,
total_amount BIGINT UNSIGNED NOT NULL,
paied_amount BIGINT UNSIGNED NOT NULL
);
Pitfalls of Table Creation
Some databases like MySQL have a syntax: create tables as select, which means that the table is created and data is copied from another table to the new table, but there will be a problem that all constraints and indexes will be lost. Here is an example:
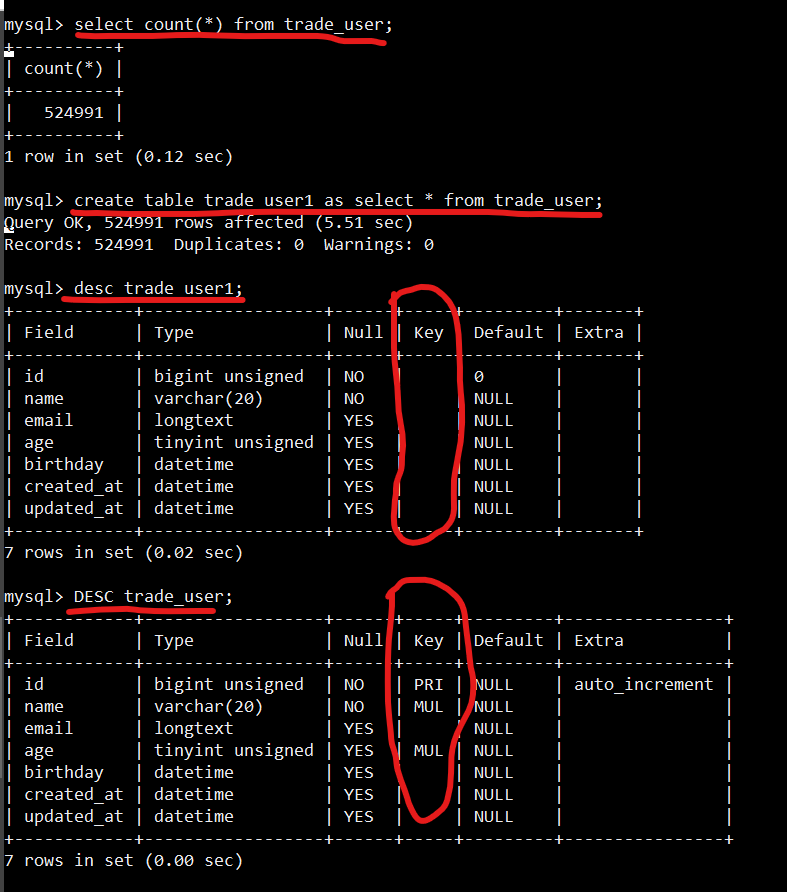
Proper Method
Before using unfamiliar SQL, make sure to understand all its features.
Modify Table
The alter table statement is used to modify tables in MySQL. The syntax for alter table is a bit complex, so we often use tools to create SQL statements for modifications like these.
ALTER TABLE tbl_name
[alter_option [, alter_option] ...]
[partition_options]
alter_option: {
table_options
| ADD [COLUMN] col_name column_definition
[FIRST | AFTER col_name]
| ADD [COLUMN] (col_name column_definition,...)
| ADD {INDEX | KEY} [index_name]
[index_type] (key_part,...) [index_option] ...
| ADD {FULLTEXT | SPATIAL} [INDEX | KEY] [index_name]
(key_part,...) [index_option] ...
| ADD [CONSTRAINT [symbol]] PRIMARY KEY
[index_type] (key_part,...)
[index_option] ...
| ADD [CONSTRAINT [symbol]] UNIQUE [INDEX | KEY]
[index_name] [index_type] (key_part,...)
[index_option] ...
| ADD [CONSTRAINT [symbol]] FOREIGN KEY
[index_name] (col_name,...)
reference_definition
| ADD [CONSTRAINT [symbol]] CHECK (expr) [[NOT] ENFORCED]
| DROP {CHECK | CONSTRAINT} symbol
| ALTER {CHECK | CONSTRAINT} symbol [NOT] ENFORCED
| ALGORITHM [=] {DEFAULT | INSTANT | INPLACE | COPY}
| ALTER [COLUMN] col_name {
SET DEFAULT {literal | (expr)}
| SET {VISIBLE | INVISIBLE}
| DROP DEFAULT
}Guide to Modifying Tables
MySQL 8.0 supports the Instant modification of table structure, but it can only be done up to 64 times. After reaching this limit, it will default to a table rebuild. More details can be found in the following references:
- MySQL 8 INSTANT Add or Delete Column (Solution to issues with adding/removing large table column)
- 【Translation】"Instant Addition and Deletion of Column" Function in MySQL 8.0
Delete Table
Deleting a table in MySQL is pretty straightforward, but it needs to be executed cautiously.
DROP [TEMPORARY] TABLE [IF EXISTS]
tbl_name [, tbl_name] ...
[RESTRICT | CASCADE]Note
Important things to remember:
Always backup the full data before deletion.
Always backup the full data before deletion.
Always backup the full data before deletion.
Searching for Tables in Database
MySQL has two ways to search for tables in a database, similar to searching for databases:
- SHOW TABLES
- Search the data dictionary.
SQL statement:
-- Using SHOW TABLES
show tables in database_name
-- Using data dictionary way
SELECT `TABLE_NAME`
FROM `INFORMATION_SCHEMA`.`TABLES`
WHERE `TABLE_SCHEMA`='database_name';Inserting rows into a table
We insert rows into the two tables we defined above. Here are some ways to perform insertions:
-- Regular INSERT
INSERT INTO trade_user (name, email, age, birthday, created_at, updated_at) VALUES
('Alice', 'alice@example.com', 30, '1992-01-10 08:30:00', NOW(), NOW()),
('Bob', 'bob@example.com', 35, '1987-05-20 14:45:00', NOW(), NOW()),
('Charlie', 'charlie@example.com', 25, '1997-08-15 09:00:00', NOW(), NOW()),
('Diana', 'diana@example.com', 28, '1994-04-16 17:30:00', NOW(), NOW()),
('Eva', 'eva@example.com', 32, '1990-11-11 12:00:00', NOW(), NOW()),
('Frank', 'frank@example.com', 40, '1982-12-03 19:15:00', NOW(), NOW());
-- INSERT INTO SELECT
INSERT INTO trade_order (user_id, order_no, created_at, updated_at, total_amount, paied_amount)
SELECT 1000 AS user_id, 1000001 AS order_no, NOW() AS created_at, NOW() AS updated_at, 2500 AS total_amount, 2500 AS paied_amount
UNION ALL
SELECT 1001, 1000002, NOW(), NOW(), 3000, 3000
UNION ALL
SELECT 1002, 1000003, NOW(), NOW(), 4000, 4000
UNION ALL
SELECT 1003, 1000004, NOW(), NOW(), 5000, 5000
UNION ALL
SELECT 1004, 1000005, NOW(), NOW(), 6000, 6000
UNION ALL
SELECT 1005, 1000006, NOW(), NOW(), 7000, 7000;Deleting rows
To delete rows from a table, we use the DELETE statement.
MySQL delete syntax:
DELETE [LOW_PRIORITY] [QUICK] [IGNORE] FROM tbl_name [[AS] tbl_alias]
[PARTITION (partition_name [, partition_name] ...)]
[WHERE where_condition]
[ORDER BY ...]
[LIMIT row_count]Avoid pitfalls in deleting rows
- In production environment, do not use the data queried by select as a condition for deletion. Let DevOps locate all the satisfying IDs to be deleted. If one batch isn’t enough, delete in multiple batches. Always backup data prior to deletion.
- When deleting all the rows from a table online, do not directly use
delete from xxx, or your binlog, downstream replication, DevOps and users will all be affected; Backup, backup, backup – always backup, whether it’s full table backup or incremental backup. Use truncate table. If truncate table can’t be used, delete in batches and optimize afterwards.
SELECT Query
Most of our time is spent on the SELECT query, which can be quite varied. I haven’t been able to fully grasp its complexity yet.

Simple Queries
select 1;
select 1 as id;
select * from trade_user;
select username from trade_user;
select username as uname from trade_user;
select distinct username from trade_user;
WHERE Clause
Comparison Operators:
select * from trade_user where id>10;
where id < 10;
where id=10;
where id != 10;
where id <> 10;Logical Operators:
select * from trade_user where id=1 and username='';
where id=1 or id=2;
where not id=1;
where not id=1 and not id=2;
where not id=1 or not id=2;
where not (id=1 or id=2);Tips for Logical Operators
Queries that use both AND and OR are considered complex. As much as possible, use indexes that have high discrimination. Otherwise, you will have to resort to index range and Index merge.
IN Query
select * from trade_user where age in (12, 13);
select * from trade_user where age in (select age from trade_user);
select * from trade_user where (name, age) in (select name, age from trade_user);
select * from trade_user where (name, age) in (select name,age from trade_user where id=1);
select * from trade_user where (name, age) in (('b', 12));Avoiding Pitfalls with IN
In has null value.
Insert one record:
insert into trade_user (name, email, age, birthday, created_at, updated_at) values('fofcn.tech', 'fofcn@fofcn.tech', null, '1989-05-25 00:00:00', now(), now());Query the just inserted data:
select * from trade_user where age in (null);It couldn’t be found.

Let’s try a different method:
select * from trade_user where age is null;The data can now be found.

Why is this?
In SQL, NULL is not a specific value, but represents an "unknown" state. If you use the IN operator to query NULL, you may run into problems.
This is because in SQL, NULL compared with any other value (including another NULL) will return NULL, not a boolean value TRUE or FALSE.
Have you ever tried nil == nil in Go?
LIKE for Fuzzy Query
select * from trade_user where `name` like '%al%';
select * from trade_user where `name` like '%al';
select * from trade_user where `name` like 'al%';Heard that if % is on the left, index won’t be used? You don’t get to decide.
It depends on the situation, it’s not absolute that index won’t be used when % is on the left. For example, our trade_user table.
Our table has over 500,000 records, with 3 indexes: Primary Key, idx_name, idx_age.
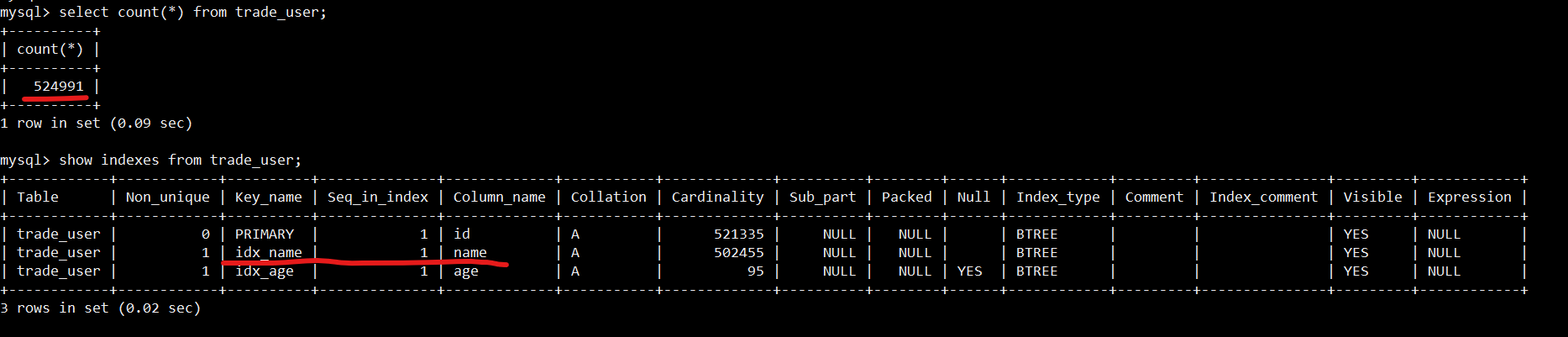
First SQL: Query all user information, the condition is that the username contains 51.
explain select * from trade_user where name like '%51';The result is indeed not using index, full table scan.

Second SQL: Query user’s name, condition remains same.
explain select name from trade_user where name like '%51';The result is that the index was used, and it’s a covering index.

Third SQL: Query user’s id and name, condition remains same.
explain select id,name from trade_user where name like '%51';The result is exactly the same as the second SQL.

Fourth SQL: Query user’s id, name and birthday, condition remains same.
explain select id,name,birthday from trade_user where name like '%51';The result is exactly the same as the first SQL, full table scan

Limit M OFFSET
The LIMIT clause can be used to constrain the number of rows returned by the SELECT statement. LIMIT takes one or two numeric arguments, which must both be nonnegative integer constants, with these exceptions:
- Within prepared statements, LIMIT parameters can be specified using ? placeholder markers.
- Within stored programs, LIMIT parameters can be specified using integer-valued routine parameters or local variables.
select * from trade_user limit 20000000, 10
select * from trade_user limit 10 offset 20000000
Limit M OFFSET N Pitfall
Reference: MySQL limit N offset M slow? Let’s experience it
Aggregate Queries
Count
// Count the whole table
select count(*) from trade_user;
// Count distinct
select count(distinct name) from trade_user;
// Count the whole table
select count(1) from trade_user;
// Field count, if id is null, it will not be included in the total
select count(id) from trade_user;
// Group count
select count(*) from trade_user group by email;
Let’s discuss count(*), count(1), count(column) again
count() count: only +1 if there is a row, regardless of column value
count(1):
count(column): column is not empty +1, otherwise +0
Result: count() = count(1) = count(id) = count(non-null column) != count(possible null column)
What? What I said is wrong? Then you still look at Stackoverflow’s statement ?: What is better in MYSQL count(*) or count(1)?
Take a look at the statement of the MySQL official website: MySQL Aggregation Function
*InnoDB handles SELECT COUNT() and SELECT COUNT(1) operations in the same way. There is no performance difference. MyISAM COUNT(1) is only subject to the same optimization if the first column is defined as NOT NULL.**
Sum
select sum(paid_amount) from trade_order;
Sum Pitfall
sum() may return null, at this time the application layer needs to judge or use database functions to deal with:
select COALESCE(sum(paid_amount), 0) from trade_order;
select IFNULL(sum(paid_amount), 0) from trade_order;
sum() may overflow, but don’t usually worry, the general processing of money problems are bigint and based on cents, if overflowed means that your company’s efficiency is against the sky, ascend to 90,000 miles.
sum() may have performance problems, in case your condition is a full table scan and there are a lot of data, then GG, so you can use alternative solutions, such as: redis’s incr always add or subtract can replace some kind of sum.
Average Value
select avg(paid_amount) from trade_order;
Maximum Value
select max(paid_amount) from trade_order;
Minimum Value
select min(paid_amount) from trade_order;
Connection (join)
Inner Connection(inner join)
Only when the matching condition on both sides has a value, the record will be returned:
select * from trade_user u inner join trade_order r on r.user_id=u.id;
inner join returns duplicate records in the one-to-many relationship, remember to deduplicate.
Left Connection(left join)
The left table has a value but the right side does not match, the returned result set right table is empty:
select * from trade_user u left join trade_order r on r.user_id = u.id;
Which is the left table? trade_user because it’s on the right side of the JOIN.
Left join returns duplicate records in the one-to-many relationship, remember to deduplicate.
Right Connection(right join)
The left table has a value but the right side does not match, the returned result set right table is empty:
select * from trade_user u right join trade_order r on r.user_id = u.id;
Which is the right table? trade_order because it’s on the right side of the JOIN.
Right join returns duplicate records in the one-to-many relationship, remember to deduplicate.
Cartesian Product(product)
-- The first Cartesian product mode
select * from trade_user, trade_order;
-- Sedentarization
select * from trade_user join trade_order;Pitfalls
Subquery (subqueries)
The subquery is a SELECT statement nested in another SQL statement. Its purpose is usually to process complex business logic, and the processed results can be used as external query conditions. Subqueries can be nested in SELECT, INSERT, UPDATE, DELETE statements, and another subquery.
Subquery classification:
- Correlated subqueries (correlated subquery) non-correlated subqueries are independent queries, and the results of subqueries do not depend on external queries. They are usually parsed and executed first during execution, and then the result set is returned to the external query for use.
- Non-correlated subqueries (non-correlated subquery) The related subqueries depend on the external query, and each row of the external query result needs to execute a subquery. Related subqueries are executed, and a subquery operation is performed for each record of the external query.
Non-Correlated Subquery
select id from trade_user where id > 100000 does not depend on the external query.
select * from trade_order where user_id in (select id from trade_user where id > 100000);
Related Subqueries
The subquery select 1 from trade_order o where o.user_id=u.id depends on the external query.
select u.id, u.name from trade_user u where u.id=1 and exists (select 1 from trade_order o where o.user_id=u.id) ;Sorting (ordering)
order by age;
order by age desc;
order by age desc, id asc;
order by age + id;
order by date(created_at);
order by alias_age;
Sorting Pitfalls
There can be issues with the SQL order by age + id; when encountering NULL values, as demonstrated by the following SQL statement:
select * from trade_user order by age + id asc limit 10;
Let’s analyze the output:
+--------+------------+------------------+------+---------------------+---------------------+---------------------+
| id | name | email | age | birthday | created_at | updated_at |
+--------+------------+------------------+------+---------------------+---------------------+---------------------+
| 525592 | fofcn.tech | fofcn@fofcn.tech | NULL | 1989-05-25 00:00:00 | 2024-04-10 09:31:24 | 2024-04-10 09:31:24 |
| 1 | b | user9@test.com | 12 | 2008-11-13 04:29:47 | 2024-03-19 13:31:11 | 2024-03-19 13:31:11 |
| 4 | User 12 | user12@test.com | 15 | 2008-11-13 04:29:47 | 2024-03-19 13:31:11 | 2024-03-19 13:31:11 |
| 8 | User 16 | user16@test.com | 11 | 2008-11-13 04:29:47 | 2024-03-19 13:31:11 | 2024-03-19 13:31:11 |
| 3 | User 11 | user11@test.com | 19 | 2008-11-13 04:29:47 | 2024-03-19 13:31:11 | 2024-03-19 13:31:11 |
| 5 | User 13 | user13@test.com | 18 | 2008-11-13 04:29:47 | 2024-03-19 13:31:11 | 2024-03-19 13:31:11 |
| 15 | User 5 | user5@test.com | 8 | 2008-11-13 04:29:47 | 2024-03-19 13:31:11 | 2024-03-19 13:31:11 |
| 16 | User 6 | user6@test.com | 7 | 2008-11-13 04:29:47 | 2024-03-19 13:31:11 | 2024-03-19 13:31:11 |
| 10 | User 18 | user18@test.com | 13 | 2008-11-13 04:29:47 | 2024-03-19 13:31:11 | 2024-03-19 13:31:11 |
| 6 | User 14 | user14@test.com | 28 | 2008-11-13 04:29:47 | 2024-03-19 13:31:11 | 2024-03-19 13:31:11 |
+--------+------------+------------------+------+---------------------+---------------------+---------------------+
10 rows in set (0.27 sec)
Intriguingly, id=525592 appears in the output. By analyzing this data, the distinguishing factor is that age=NULL. According to the database documentation, NULL in an operation results in NULL, and NULL is considered to be the minimum value in an ordering operation. Here is an example:
mysql> select 1+null;
+--------+
| 1+null |
+--------+
| NULL |
+--------+
1 row in set (0.00 sec)
select * from (
select 1+null as id
union all select 2 as id
union all select 3 as id
union all select 4 as id
) t order by id asc limit 2;
+------+
| id |
+------+
| NULL |
| 2 |
+------+
2 rows in set (0.00 sec)
select * from (
select 1+null as id
union all select 2 as id
union all select 3 as id
union all select 4 as id
) t order by id desc limit 2;
+------+
| id |
+------+
| 4 |
| 3 |
+------+
2 rows in set (0.00 sec)
Grouping
Potential Issues with Grouping
- this is incompatible with sql_mode=only_full_group_by
Reason:The SQL-92 standard and earlier versions do not permit queries in the select list, HAVING condition, or ORDER BY list to refer to non-aggregated columns that are not named in the GROUP BY clause. For example, the following query is not allowed in the SQL-92 standard because the non-aggregated column name does not appear in the GROUP BY:
SELECT o.custid, c.name, MAX(o.payment)
FROM orders AS o, customers AS c
WHERE o.custid = c.custid
GROUP BY o.custid;
To make the query legal in SQL-92, the name column must be removed from the select list or named in the GROUP BY clause.
SQL: 1999 and later versions allow such non-aggregate columns in optional feature T301, as long as they functionally depend on the GROUP BY columns: if such a relationship exists between name and custid, the query is allowed. For example, if custid is the primary key of the customers, this situation will occur.
Solution:
```sql
SELECT @@session.sql_mode;
set @@session.sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
set @@global.sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
- NULL values
union/union all
The UNION command is used to combine the result sets of two or more SELECT statements. Meanwhile, UNION will delete duplicate rows from the result set.
UNION eliminates duplicates by comparing all rows in the result set. This process corresponds to a full row comparison; only if all fields in two rows of data are exactly the same, the system will identify these two rows as duplicates and deduplicate.
Note that the UNION command only removes completely identical (all column values are the same) rows.
When using UNION, each SELECT statement must have the same number of columns, the columns must have similar data types, and the order must also be the same.
If you do not want to remove duplicate rows from the result set, you can use UNION ALL. Compared to UNION, UNION ALL does not remove duplicate rows, so it executes faster than UNION.
select 1 as id
union
select 1 as id
union
select 2 as id;
select 1 as id
union all
select 1 as id
union all
select 2 as id;
What’s the difference between union and union all?
| Differences | UNION | UNION ALL |
|---|---|---|
| Deduplication | UNION automatically removes all duplicate rows |
UNION ALL does not remove duplicate rows |
| Performance | Due to the deduplication operation, the performance of UNION may be lower than that of UNION ALL |
UNION ALL generally outperforms UNION |
| Result Set Size | The result set returned by UNION may be less than or equal to the sum of the result sets of two queries |
The result set returned by UNION ALL is exactly equal to the sum of result sets of the two queries |
| Operation | UNION performs a set union on two result sets |
UNION ALL merges two result sets, including all duplicate rows |
Example:
select 1 as id
union
select 1 as id
union
select 2 as id;
+----+
| id |
+----+
| 1 |
| 2 |
+----+
2 rows in set (0.00 sec)
select 1 as id
union all
select 1 as id
union all
select 2 as id;
+----+
| id |
+----+
| 1 |
| 1 |
| 2 |
+----+
3 rows in set (0.00 sec)
select 1 as id, 2 as name
union
select 1 as id, 3 as name
union
select 2 as id, 1 as name;
+----+------+
| id | name |
+----+------+
| 1 | 2 |
| 1 | 3 |
| 2 | 1 |
+----+------+
3 rows in set (0.00 sec)
select 1 as id, 2 as name
union
select 1 as id, 2 as name
union
select 2 as id, 1 as name;
+----+------+
| id | name |
+----+------+
| 1 | 2 |
| 2 | 1 |
+----+------+
2 rows in set (0.00 sec)Window Functions
Comparison between window functions and Group By
Handling Nulls
The casual version of the above content is as follows:
-
Representing unknown or missing information:
NULLcan be understood as a "I don’t know" or "information is missing" status in some data. -
Cannot be compared in a regular way:
NULLis not equal to any value, including itself. We cannot use=,<, or<>operators to check if a value isNULL, but we can useIS NULLorIS NOT NULL. -
Special position in sorting: When sorting, such as using
ORDER BY,NULLis usually treated as the smallest value. If you sort in ascending order,NULLwill be at the front; if in descending order,NULLwill be at the end. -
Unknown result when involved in an operation: In mathematical operations, the result is
NULLno matter what number the operation is with, as long asNULLis involved. -
Ignored in statistical operations: In statistical operations,
NULLis usually ignored, but if we count all rows, such as withCOUNT(*),NULLwill be counted. -
False in logical judgments: In MySQL,
NULLand zero are both considered false, while other non-zero and non-NULLvalues are considered true. -
Can be indexed: If you use MyISAM, InnoDB or MEMORY storage engines, you can add an index on a column that may have
NULLvalues. -
Considered the same in grouping: When we do grouping calculations, all
NULLs are treated as the same. -
Applicable to all data types: Almost all data types can contain
NULL, andNULLitself does not have a data type. -
Does not prevent the insertion of zero or empty strings: Even if the column is set to
NOT NULL, zero or empty strings can be inserted completely, because the real rejection isNULL, while zero and empty strings are specific values. -
Cannot be queried via the in operator: For example, the query
select * from trade_user where age in (null)does not return any results, becauseNULLcannot be directly queried. To queryNULLvalues, you should use theIS NULLstatement.
Update Operations
Delete Operations
Indexing
Tuning
Transactions
About transactions and transaction isolation level, you can refer to:
- MySQL Transactions and Transaction Isolation Levels
- Quickly distinguish between MySQL current reading, snapshot reading and phantom reading
- Current reading, snapshot reading, dirty reading, phantom reading and non-repeatable reading
Locks
For more information on locks, you may refer to:
Internals
Join
For more information on join, you may refer to: